
AI Image Generation via SMS
We added AI-generated images to RidgeText so users can ask for a picture of anything and receive it as an MMS — no app, no data plan required beyond basic SMS. This is the story of how we tested and selected the models behind that feature.
March 7, 2026
One of the most surprisingly delightful capabilities of modern multimodal AI is generating images from natural language descriptions. For RidgeText, being an SMS-first AI assistant, this opens up a genuinely useful dimension: a hiker can text “show me what poison oak looks like”, a parent can ask for a bedtime story illustration, or anyone can simply satisfy curiosity with a quick picture request, all without opening an app.
Delivering images over SMS is more constrained than a web interface. The image has to be compact enough to fit in an MMS, generated quickly enough that the reply doesn't feel slow, and good enough that users actually find it useful. That means model selection matters.
With the deprecation of Gemini 3.0, we ran a systematic evaluation of three models: Gemini 3.1, Imagen 4.0, and Gemini 2.5. The goal was to pick a primary model and define a fallback chain for when the primary is unavailable or refuses a request. Below is a walkthrough of every image we generated, in the order we generated it.
Gemini 3.0 — The Original Baseline
We started with Gemini 3.0, which was the stable, generally available model at the time. It produced solid results — but a deprecation notice for Gemini 3.0 Pro suggested that we upgrade our image generation immediately, so we could ship it as the primary model.
 Gemini 3.0
Gemini 3.0Prompt: Generate an image of a whale breaching
A humpback whale breach under a partly cloudy sky. The anatomy is accurate, the spray is realistic, and the composition is well-centered. It reads as a solid nature photograph — competent and usable. The quality was good enough to ship, but the model was heading for deprecation in early March 2026, so we needed to find what came next.
With Gemini 3.0 off the table, the obvious next step was its predecessor: Gemini 2.5. We needed to establish a new baseline before layering in anything more capable.
Gemini 2.5 — New Baseline
Gemini 2.5 is the stable GA predecessor to 3.0. While being older than 3.0, it produces images much faster and seems to be still available. It is a decent fallback safety net — the model that always delivers something usable when everything else fails.
Something that differentiates Gemini 2.5 images in RidgeText is that they are always generated as 1024x1024 square format, regardless of the aspect ratio requested. This square format is an easy indication that a fallback event occurred and you might not be getting the best possible image for your prompt.
We will eventually deprecate Gemini 2.5 as new models become available, but for now it serves as a reliable final fallback in the chain. Any image that falls back to Gemini 2.5 is still a usable result, just without the potential quality or contextual reasoning benefits of the newer models.

Prompt: Generate an image of an elephant
An elephant at golden hour, acacia trees behind it casting long morning shadows. The rendering is warm and slightly soft — less edge-sharp than a dedicated image model, but still high quality and immediately readable as a nature photograph. This became our benchmark: anything we add to the pipeline needs to beat this, or it isn't worth the added complexity.

Prompt: Generate an image of a monkey
Where Gemini 2.5 gets interesting is its aesthetic variability. Here, instead of a photorealistic wildlife shot, it produced something closer to digital concept art — a spider monkey surrounded by electric-blue morpho butterflies and vivid heliconia, with a supersaturated palette that feels constructed rather than observed. Visually striking, but stylistically unexpected. This range is worth understanding: the fallback model isn't always going to match the primary's style.

Prompt: Generate an image of a monkey
A second attempt at a similar subject lands much closer to photorealism. A capuchin monkey on a moss-covered branch, raindrops on surrounding leaves, tropical flowers in the mid-ground. The fur detail is precise, the atmospheric moisture reads convincingly, and the composition is natural. Gemini 2.5 can clearly deliver photorealistic results — the output style is just less predictable than a purpose-built image model. As a final fallback, that's acceptable.
Gemini 2.5 established a solid floor. The next question was whether a purpose-built image model could raise the ceiling — specifically for photorealistic wildlife and nature photography, which is exactly what RidgeText users ask for most.
Imagen 4.0 — Quality Upgrade
Imagen 4.0 is Google's dedicated image generation model, purpose-built for photorealism. It produces sharper, more detailed results than Gemini 2.5 — at the cost of speed and with some edge cases worth documenting.

Prompt: Generate an image of an elephant
The first Imagen 4.0 elephant. The model produced a dramatic close crop of an elephant raising its curled trunk — and added five birds perched along it. Nobody asked for birds.
Compositionally it's a beautiful image. The tight framing, the dust catching backlight, the oxpecker-type birds along the trunk — it works as wildlife photography. But it's a reminder that models occasionally add elements that feel contextually appropriate without being requested, and which are not possible in reality -- given the trunk would be moving in this image (anyone play Angry Birds?).
The response: ask again, this time explicitly ruling out birds.

Prompt: Generate an image of an elephant, no birds
With "no birds" explicit in the prompt, none appear. The model produced a dynamic action shot instead — an elephant blowing a cloud of dust from its trunk, the particle dispersion physically accurate with heavier particles near the ground and finer dust rising into the light. Negative constraints work when stated clearly. But the question was still open: could Imagen 4.0 match the deep skin texture detail we'd seen in Gemini 3.1's earlier testing?
 Imagen 4.0
Imagen 4.0Prompt: Generate an image of a photorealistic elephant with deep wrinkles in its skin
Pushing for the detail we wanted: a photorealistic elephant with deep skin wrinkles. The result is exactly that. This elephant walks across open golden savanna at late afternoon, acacia trees silhouetted behind it, and the skin wrinkle detail is exceptional — every fold and crease distinct, looking genuinely three-dimensional in a way that directly competes with Gemini 3.1's best results. This image made the case for Imagen 4.0. The quality ceiling is real, the issue is that the user is required to explain every detail to get the right quality, and this image took a couple of minutes to generate instead of seconds.

Prompt: Generate an image of a whale breaching
A humpback whale breach in clean profile. The full body is airborne, showing the distinctive ribbed ventral pleats, long pectoral fins, and tubercles along the rostrum. Water spray trails from the body. Anatomically accurate (almost, notice multiple eyes on one side), well-composed. A textbook result.

Prompt: Generate an image of a whale breaching (second attempt)
Like a mad science experiment gone wrong. An extreme close crop of a humpback's head and upper torso at re-entry — the body fills the frame edge-to-edge, the eye is near the fin, the fins are either backwards or the mouth is mysteriously behind the fins. It is cut off in a way that reads as confusing rather than dramatic.
Model quality and compositional judgment are separate dimensions. For SMS delivery where the user can't request a retake, this is a real failure mode.

Prompt: Generate an image of a monkey in forest
A macaque-type monkey in a sun-dappled forest interior, gazing upward. Soft directional light, fine fur strand detail, accurate facial anatomy, tasteful background bokeh. A photorealistic result with consistent quality — unlike Gemini 2.5, Imagen 4.0 doesn't drift toward the illustrative end of the spectrum on this type of subject.
 Imagen 4.0
Imagen 4.0Prompt: Generate an image of a whale breaching
Imagen 4.0 at its best. A humpback launches nearly vertically at sunrise, pale belly lit from below by reflected golden light, water streaming in dramatic curtains. A handful of seagulls add scale and context. The composition is centered and balanced, the lighting is cinematic, the anatomy is flawless. This is the image that confirmed Imagen 4.0 should be in the chain — it out-performs Gemini 2.5 clearly enough at this type of subject to justify the additional latency.
Imagen 4.0 produces better photorealistic images than Gemini 2.5, but it's slower and uses a different API method. We now had a good fallback chain: Imagen 4.0 → Gemini 2.5. The remaining question was the primary: what model should go first for speed and breadth?
Gemini 3.1 — The Fast, Capable Primary
Gemini 3.1 Flash Image became the primary model. It's faster than Imagen 4.0 for straightforward prompts and supports variable thinking — meaning it can spend more reasoning effort on complex or ambiguous requests. It also handles a wider range of content types than a pure image model.

Prompt: Generate an image of a blue whale
The opening Gemini 3.1 result sets an immediate quality bar. A blue whale glides through deep ocean, sunbeams piercing the surface above, a small school of fish visible in the background. Skin texture — mottled grey-blue with ventral pleats — is rendered with the detail of an underwater photograph. Lighting physics are accurate: caustic patterns on the water surface, the gradient from bright near-surface to deep dark below. This level of quality at the speed Gemini 3.1 operates at is what made it the primary.
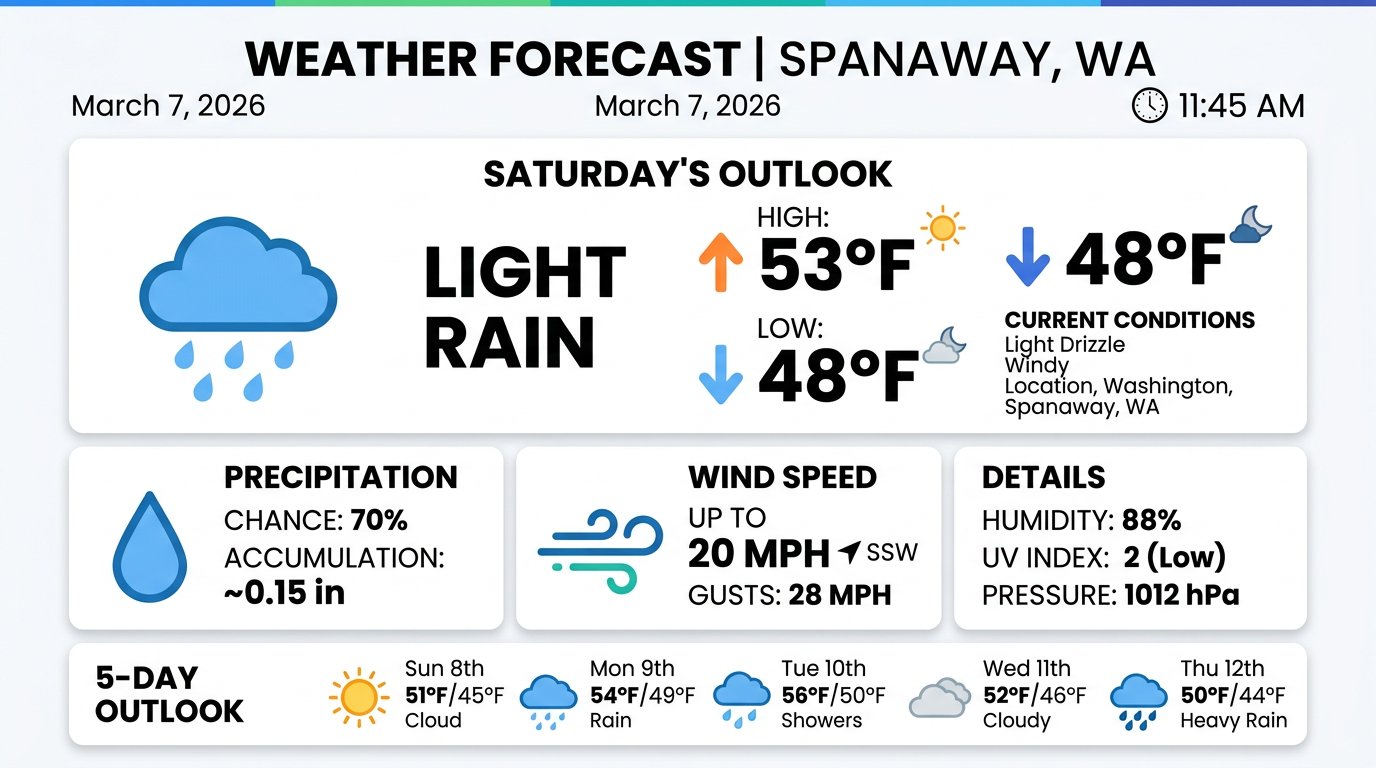
Prompt: Generate an image of a weather forecast (card format)
This is where Gemini 3.1 separates itself from a pure image model like Imagen 4.0. Asked for a weather forecast visualization, it produced a fully coherent infographic card — structured data layout with a current conditions block, precipitation and wind speed panels, and a 5-day forecast strip. Clean typography, recognizable weather icons, internally consistent data. Imagen 4.0 cannot do this. This breadth is exactly why Gemini 3.1 is the primary and Imagen 4.0 is the fallback, not the other way around.
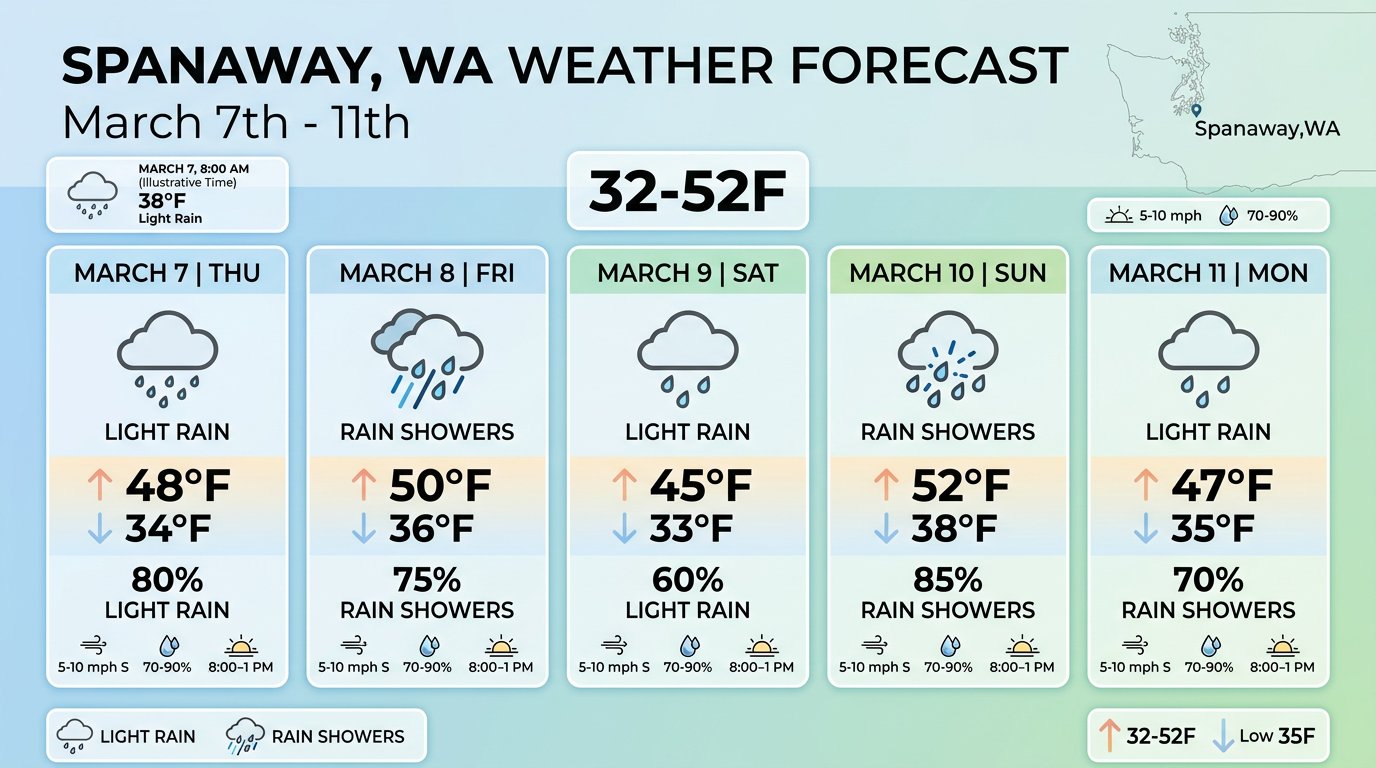
Prompt: Generate an image of a weather forecast (multi-day layout)
A second weather visualization — this time a multi-day column layout for March 7–11th, with a state map inset. Distinct format from the first card, demonstrating the model isn't just templating a fixed design. Both weather images reflect Gemini 3.1's ability to reason about structured data and render it as a coherent graphical layout — a capability that directly benefits RidgeText's weather feature.

Prompt: Generate an image of a gorilla
A portrait of a silverback gorilla in dense jungle vegetation. Individual fur strands catch light, skin folds on the face are anatomically accurate, the wet-looking coat has a natural sheen. Gemini 3.1 demonstrates genuine photographic fidelity here — not just plausible approximation. For the wildlife queries that make up the bulk of RidgeText image requests, this quality level from the primary model means Imagen 4.0 fallback is rarely needed.

Prompt: Generate an image of an old woman in a desert with sun damaged skin and eyes that have seen a lot
An elderly woman in traditional desert dress against a backdrop of sand dunes and rocky outcrops. Skin texture is rendered carefully — sun-weathered, deeply lined — with the silver necklace and rough-spun headscarf adding authentic detail. The warm desert light is consistent across the scene. Human portrait fidelity is historically a harder problem for generative models; Gemini 3.1 handles it well.

Prompt: Generate an image of an old woman in a desert with sun damaged skin and eyes that have seen a lot
The same subject in a tighter close-up with a darker blue headscarf and dramatic golden-hour sky. The closer framing reveals extraordinary skin texture detail — every line and fold defined, the eyes catching reflected light, the fabric showing individual fiber texture. Arguably the most technically impressive portrait in the set.
 Gemini 3.1
Gemini 3.1Prompt: Generate an image of a forest fire based on news reports of any wildfire currently happening in the US
This prompt demonstrates one of RidgeText's most powerful capabilities: chaining tasks together in a single request. Rather than just generating an image, RidgeText first searched for current wildfire news in the US, then used those results to inform the image generation. The result is a full wildfire scene — firefighters in yellow Nomex gear on a gravel mountain road, a red fire truck following, orange flames consuming a stand of pines, smoke billowing into a clear blue sky — grounded in real current events rather than invented from whole cloth. This is where variable thinking pays off. The model reasoned through a multi-step task: find news, extract relevant visual detail, then render a coherent scene. It looks like a news photograph because it was inspired by one. RidgeText has the ability to search and reason across tasks.
 Gemini 3.1
Gemini 3.1Prompt: Generate an image of a whale jumping over a rocky outcrop like Free Willy
A cultural reference test: the iconic orca breach from the 1993 film Free Willy. Gemini 3.1 produced an orca leaping over a sea stack at dusk, a dramatic storm-lit sky behind it, spray catching the last orange light. The composition mirrors the emotional weight of the reference image without being a direct copy. This kind of cultural reasoning is unique to Gemini 3.1 in the chain. That said, even Gemini 3.1 isn't perfect. We can see that the whale has chosen a rather shallow rocky outcrop that it may not actually clear, which is a reminder that the model's understanding of physical reality isn't flawless, especially when artistic or cinematic license is involved.

Prompt: Generate an image of an elephant
Going back to our standard elephant prompt. Gemini 3.1 created an elephant approaching through dense green bush — Good subject detail and solid prompt adherence. Running this alongside the Gemini 2.5 and Imagen 4.0 elephant results shows Gemini 3.1 sitting well above them in photorealistic precision and ahead of both in contextual interpretation.
The Resulting Architecture
The production pipeline tries models in order, moving to the next on any failure. Aspect ratios unsupported by a model are automatically bucketed to the nearest supported ratio rather than failing.
| Model | Typical Speed | Notes |
|---|---|---|
| Gemini 3.1 Flash Image | 4–6s (MINIMAL thinking) | +60–120s with HIGH thinking; level selected by the LLM |
| Imagen 4.0 Fast | Variable | No thinking overhead; latency scales with prompt complexity |
| Gemini 2.5 Flash Image | 3–4s | Fastest and most consistent of the three |
Handles the full range of content types: wildlife, portraits, infographics, cultural references, and current-events imagery via search chaining. The breadth that a pure image model cannot match.
The chat LLM selects the thinking level at request time based on its interpretation of prompt complexity. MINIMAL (default) is fastest; HIGH adds 60–120s and is reserved for text-in-image or precise multi-object spatial layouts.
Purpose-built photorealism. Higher ceiling than Gemini 3.1 for detailed wildlife and nature photography. Kicks in when the primary is unavailable or rate-limited.
Stable GA model. Consistently delivers usable images across a wide range of subjects, ensuring users always receive a response even when the first two models fail.
Always outputs a square image regardless of the requested ratio. A square result is a reliable signal that a fallback event occurred.
Gemini 3.0 is no longer in the chain. What started as the original baseline became the prompt that drove the whole evaluation — its deprecation forced us to find something better, and in doing so we ended up with a pipeline that's faster, more capable, and more resilient than before.
Model selection isn't a one-time decision. The landscape changes quickly, and building a fallback chain from the start means you can swap individual links without touching the rest of the pipeline.