If you ask RidgeText to generate a fire perimeter map with trails overlaid, the response now includes a map with fire perimeters and your trail route layered on top — all rendered in a single image and sent via SMS.
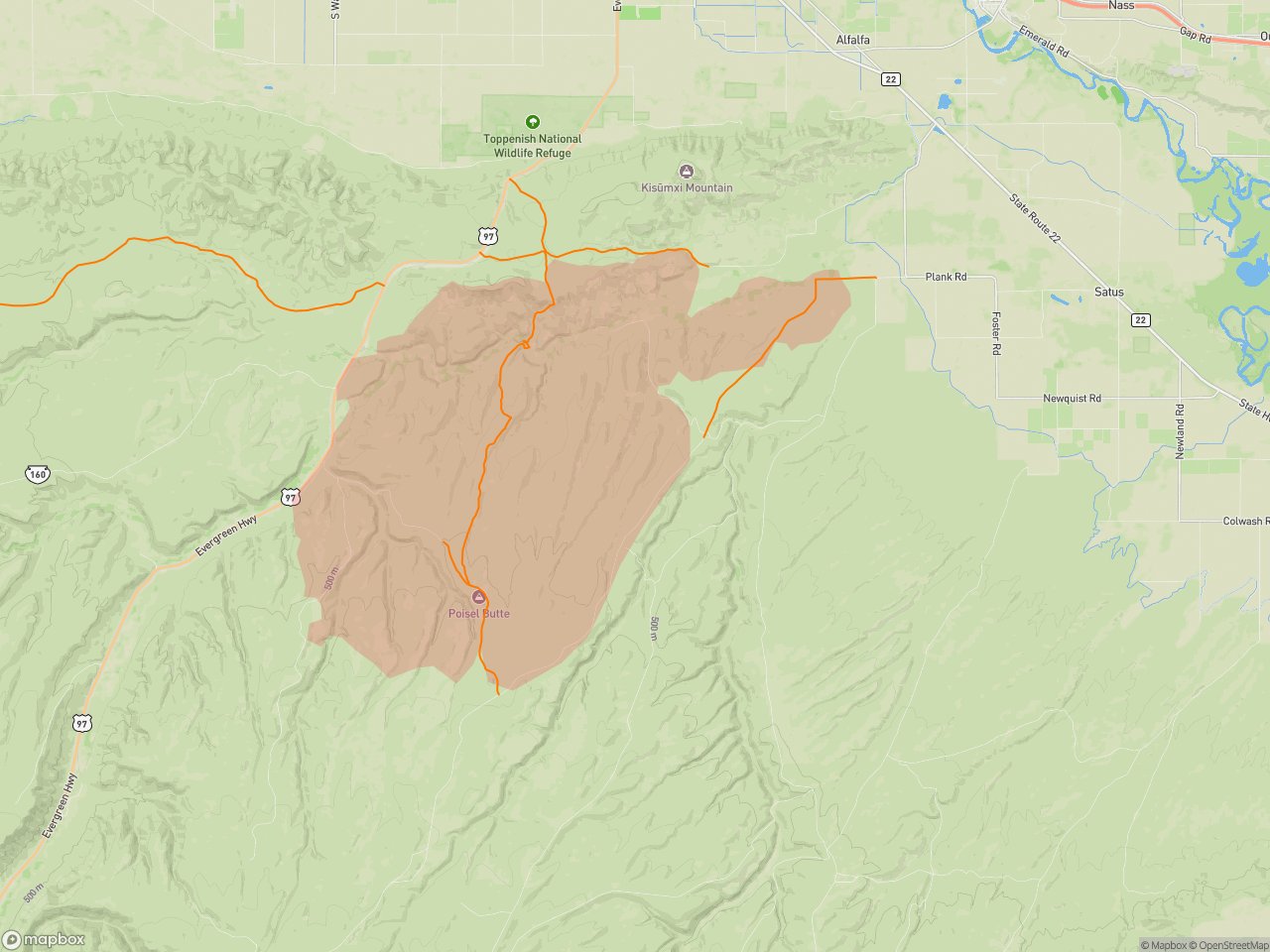
Fire perimeter (shaded polygon) with a trail route overlaid. Each of these is a separate layer queued independently before the map is rendered.
While developing this layering feature, we realized one thing: you cannot pass GeoJSON through an LLM tool call, it's simply too much data to be useful.
Background
RidgeText is built as an orchestration layer on top of an LLM. Users interact through SMS — no app, no UI — and the LLM handles natural language understanding, decides which tools to call, and composes a clear response to send back. It's not a rules engine; the LLM is making judgment calls at every step.
That non-determinism is a feature for conversation, but it creates a constraint for features: anything the LLM touches needs to be resilient to variation. If a tool returns too much data, the LLM may truncate, hallucinate a summary, or fail silently. If a tool's interface is ambiguous, the LLM may call it incorrectly. Good tool design means shaping what the LLM sees so that the range of reasonable responses all lead to correct outcomes.
Map generation is a clear example of where this matters.
The Naive Approach (and Why It Fails)
The obvious implementation is to have a tool that fetches fire data and returns it to the LLM, then a second tool that accepts that data and renders a map. Something like:
LLM calls get_wildfire_data() → receives 2,000 fire polygons as GeoJSON
LLM calls render_map(geojson: ...) → passes that GeoJSON along

In practice, a modest wildfire dataset is 50–500KB of raw GeoJSON. A token is roughly 4 bytes, so 500KB is ~125,000 tokens — larger than many context windows, and expensive even when it fits.
The LLM becomes a pipe for data it cannot reason about. It can't simplify the GeoJSON, it can't validate it, and it pays the full context cost every time.
The Layer-First Pattern
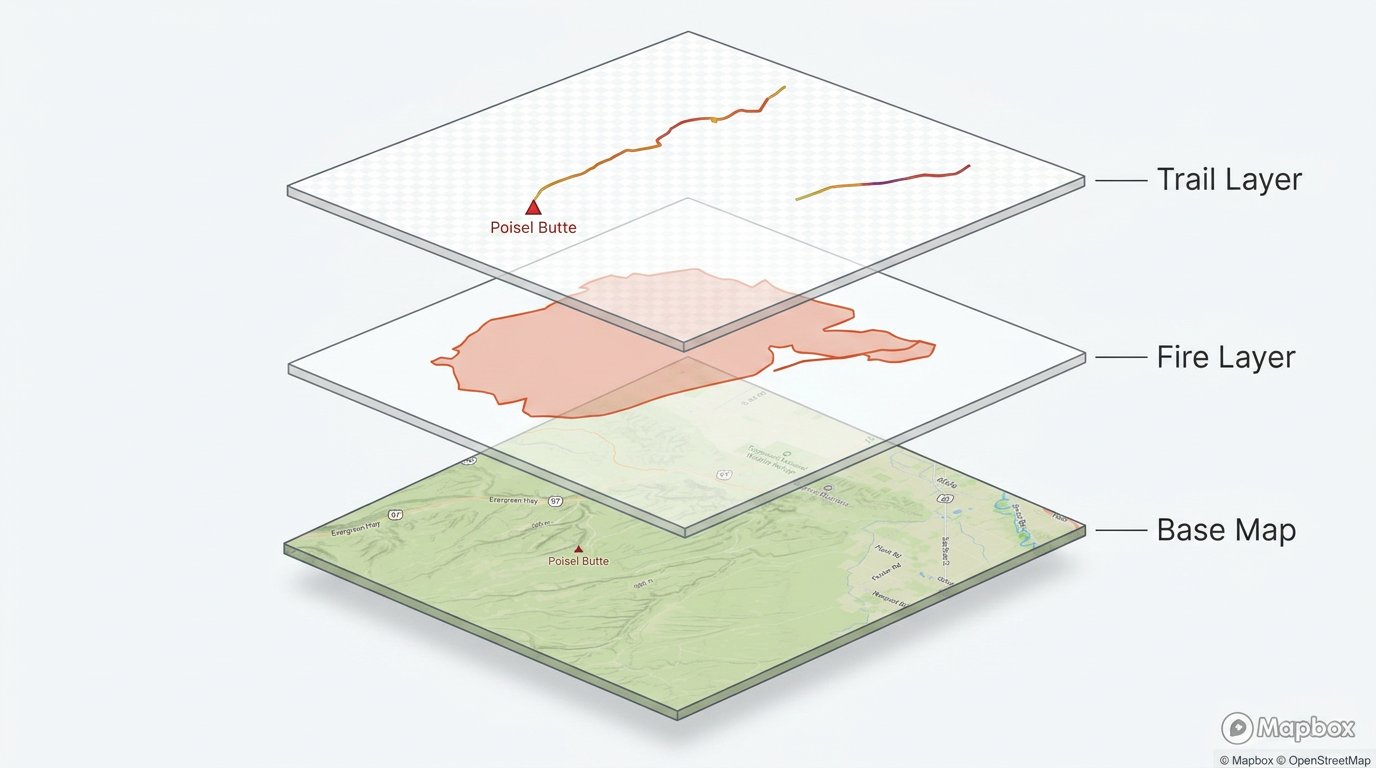
Our solution mirrors how Mapbox itself works: layers are added independently and composited at render time.
Instead of returning data to the LLM, each data-fetching tool stores its result server-side and returns only a lightweight acknowledgment:
LLM calls retrieve_wildfire_layer(location: "Cascades")
→ { status: "queued", layerId: "wildfires-0", featureCount: 847 }
LLM calls retrieve_trail_layer(trailName: "PCT Section J")
→ { status: "queued", layerId: "trail-1", featureCount: 1 }
LLM calls generate_map()
→ { mapUrl: "https://storage.../map-abc123.jpg" }

The LLM's context only ever sees the acknowledgments — tiny JSON objects. The GeoJSON lives in server memory until generate_map drains the queue and composites the image.
The Layer Stack
Each retrieve_* call appends to an ordered layer array held in the request context:
interface MapLayer {
type: 'wildfire-perimeters' | 'fire-hotspots' | 'trail' | 'heatmap' | ...;
data: GeoJSON.FeatureCollection;
style: LayerStyle;
}
// In-process queue — lives for the lifetime of one LLM turn
const layerQueue: MapLayer[] = [];generate_map renders them in insertion order — exactly like Mapbox's layer stack, where earlier layers sit below later ones. The LLM controls ordering implicitly by the sequence it calls the tools: if it calls retrieve_satellite_base before retrieve_trail, the trail draws on top of the satellite imagery.
Our implementation uses an in-process Map keyed by session ID with a 30-minute TTL, so layers that were queued but never rendered are evicted automatically rather than accumulating. The specific mechanism isn't the point — Redis, a database, or a request-scoped context object would all work. What matters is that the data lives somewhere other than the LLM's context window.
Why This Mirrors Mapbox
Mapbox's core model is: sources provide data, layers define how to render it, and layers compose in declaration order. Our server-side queue is the same abstraction, just running without a browser.
It's worth being precise about what "Mapbox" means in our renderer. We fetch a Mapbox Static API image as the base tile — terrain, roads, labels — and then composite the data layers on top of it using canvas. Mapbox itself never sees the GeoJSON; it only provides the background. The layer descriptors we store follow Mapbox's format not because the renderer requires it, but as a deliberate forward-looking choice.
If we ever outgrow static tiles — for 3D terrain, complex blending, or animated layers — we can swap the renderer for a headless Mapbox GL JS instance running in a Playwright browser. That renderer would consume the exact same layer queue without any changes to the tools or the LLM's interface. The cost and speed profile would also change: a JavaScript-based renderer can cache tiles and GL assets across requests, potentially reducing per-map costs and improving cold-start latency compared to making a fresh Static API call for every map.
This means:
- Adding a new data source is adding a new
retrieve_*tool — the render pipeline doesn't change - Layer ordering is natural to express through tool call sequence
- Styling is co-located with the layer type, not passed through the LLM
- The renderer is swappable — static tiles today, headless GL tomorrow — without touching the LLM layer
The Render Step
generate_map is deterministic. It receives no GeoJSON from the LLM — only optional parameters like zoom level or map style. It reads the layer queue, projects each feature set onto a Mapbox Static API base image, and composites them using sharp.
async function generateMap(options: MapOptions): Promise<string> {
const layers = drainLayerQueue(); // consume and clear
const base = await fetchMapboxBase(options);
const composed = await compositeLayers(base, layers);
return await uploadToStorage(composed);
}The result is a single image URL the LLM can attach to its SMS response.
What the LLM Actually Sees
For a "show me wildfires near the PCT" request, the LLM's tool call sequence looks like:
[
{ "name": "retrieve_wildfire_layer", "result": { "status": "queued", "featureCount": 847 } },
{ "name": "retrieve_trail_layer", "result": { "status": "queued", "featureCount": 1 } },
{ "name": "generate_map", "result": { "mapUrl": "https://..." } }
]Total tokens in tool results: ~150. Without this pattern: ~125,000+.
Tradeoffs
What you gain:
- Context window stays small regardless of dataset size
- Render pipeline is deterministic and testable in isolation
- Adding new layer types doesn't require changing how the LLM interacts with the system
What you give up:
- The LLM can't reason about the underlying geometry of any layer it queued. It knows a trail was added and how many features it contains, but nothing about the coordinates themselves. A question like "what's the nearest city to my trail?" can't be answered precisely from the queued layer data — the LLM would need a separate tool that returns that as text. It can, however, view the rendered map image later via the Storage link and make visual observations about the composite result.
- Layer queue is ephemeral — it doesn't survive across turns, so multi-turn map refinement requires re-fetching
The second tradeoff could be addressed by persisting layers to a database table that follows the same history retention policies as conversation responses. Each rendered map response would store its associated layers by reference, so if the user follows up — asking to zoom in, change the style, or add another data source — the layers can be rehydrated directly from the database without re-fetching from the original APIs.
Applying This to Your System
The pattern here isn't about maps. It's about recognizing when your LLM is acting as a data pipe instead of a reasoning engine — and removing it from that role.
The signal to look for: Tool A fetches data → LLM receives it → LLM passes it directly to Tool B. If the LLM isn't making a decision based on the content, it shouldn't be holding the content at all.
A few scenarios where the same approach applies:
Multi-source data enrichment. NREL provides a dataset of EV charging stations, but it's missing amenity data, real-time availability, and user reviews that other APIs carry. Rather than fetching each source and passing the merged payload back to the LLM for combination, each retrieval tool queues its dataset server-side. A compositor joins them on station ID and produces the enriched result. The LLM orchestrates which sources to pull and receives a summary — it never holds the intermediate per-source payloads or the merged dataset.
Log analysis with multiple passes. A user asks "how many errors did we have in the last hour, and what are the primary issues?" That's two analytical questions over the same underlying data. Without this pattern, you'd fetch the logs twice — once per tool call — or pass the raw log payload back to the LLM between calls. Instead, the log fetch runs once and stores the result. An error-count tool and a root-cause tool both read from the same stored dataset independently. The LLM gets two small structured answers rather than raw log data that it has no business holding.
Any ETL pipeline where the output is what matters. If you're pulling from multiple upstream sources and compositing them into a single result — a report, a dashboard dataset, a ranked list — the LLM's role is to decide what to pull and describe the result, not to participate in the merge. The intermediate state between sources belongs in your pipeline, not in the context window.